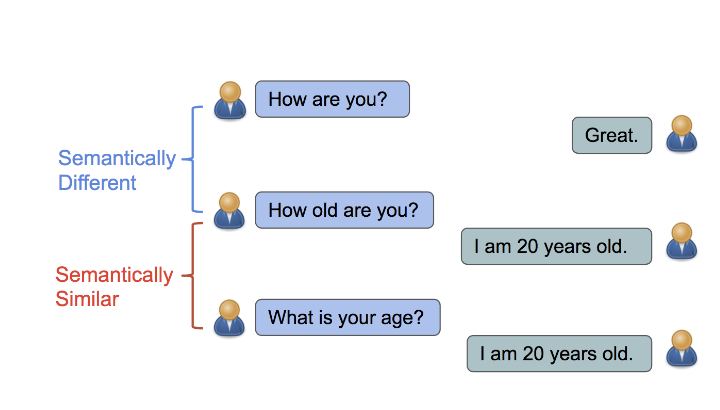
The main objective Sentence Similarity determines how similar two pieces of texts are by measuring the distance between texts. The intuition is that sentences are semantically similar if they have a similar distribution of responses. Related tasks include duplicate identification, text search & matching, question & answering, etc..
Image credit: Learning Semantic Textual Similarity from Conversations
|
Rank |
Model(s)
|
Dim |
Performance
(Spearman Correlation)
|
Model(s) from |
|---|
For each model of the sentence similarity, we evaluate its average performance on STS 2012-2016 using Spearman correlation. Refer to SentEval for details of evaluation method and source of datasets.
We can use the built-in pipeline to generate sentence embeddings, insert the embeddings into the vector database, and search in the vector database and return the similarity of sentences. More details refer to Sentence Similarity Pipeline Example.
We can use the built-in sentence_embedding pipeline to get
sentence embedding, which will use the all-MiniLM-L6-v2 model
default to generate embedding for one sentence or batch-generate embeddings
for multi-sentences.
from towhee import AutoPipes
# get the built-in sentence_similarity pipeline
sentence_embedding = AutoPipes.pipeline('sentence_embedding')
# generate embedding for one sentence
embedding = sentence_embedding('how are you?').get()
# batch generate embeddings for multi-sentences
embeddings = sentence_embedding.batch(['how are you?', 'how old are you?'])
embeddings = [e.get() for e in embeddings]The model in the pipeline can be set to the Models list above using the AutoConfig interface, refer to SentenceEmbeddingConfig Interface.
We can use the built-in insert_milvus pipeline to insert the
embedding into the Milvus vector database,
which needs to specify the name of the collection.
Before running the following code, please make sure you have created a collection, for example, named sentence_similarity, and the same dimensions(384) to the model, and the fields are id(auto_id), text(DataType.VARCHAR) and embedding(FLOAT_VECTOR).
from towhee import AutoPipes, AutoConfig
# set MilvusInsertConfig for the built-in insert_milvus pipeline
insert_conf = AutoConfig.load_config('insert_milvus')
insert_conf.collection_name = 'sentence_similarity'
insert_pipe = AutoPipes.pipeline('insert_milvus', insert_conf)
# generate embedding
embedding = sentence_embedding('how are you?').get()[0]
# insert text and embedding into Milvus
insert_pipe(['how are you?', embedding])
You can also set host and port parameters for
Milvus, and if you are a Cloud user,
there are also user and password parameters, refer
to MilvusInsertConfig Interface.
After inserting sentence embeddings into Milvus, we can search the sentence
and get the similar results with the built-in
search_milvus pipeline, which needs to specify the name of the
collection. And set
search_params = {'output_fields': ['text']} to return the
'text' field.
Before searching in Milvus, you need to load the collection first.
from towhee import AutoPipes, AutoConfig
# set MilvusSearchConfig for the built-in search_milvus pipeline
search_conf = AutoConfig.load_config('search_milvus')
search_conf.collection_name = 'sentence_similarity'
search_conf.search_params = {'output_fields': ['text']}
search_pipe = AutoPipes.pipeline('search_milvus', search_conf)
# generate embedding
embedding = sentence_embedding('how old are you?').get()[0]
# search embedding and get results in Milvus
search_pipe(embedding).get_dict()
You can also set host and port parameters for
Milvus, and if you are a Cloud user,
there are also user and password parameters, refer
to MilvusSearchConfig Interface.
name: str The name of the built-in pipeline, such as
'sentence_embedding', insert_milvus and
'search_milvus'. config: REGISTERED_CONFIG
AutoConfig is registered with the pipeline name, which defaults to
AutoConfig.load_config(name), such as if the name is
sentence_embedding and config defaults to
AutoConfig.load_config('sentence_embedding').
The code AutoConfig.load_config('sentence_embedding') will return
an auto-set SentenceSimilarityConfig object that automatically
configures some parameters of the sentence embedding pipeline:
model: str
The model name in the sentence embedding pipeline, defaults to
'all-MiniLM-L6-v2'. You can refer to the above Model(s) list
to set the model, some of these models are from
HuggingFace (open source), and some
are from OpenAI (not open, required API
key).
openai_api_key: str
The api key of openai, default is None. This key is required
if the model is from OpenAI, you can check the model provider in the above
Model(s) list.
customize_embedding_op: str
The name of the customize embedding operator, defaults to
None.
normalize_vec: bool
Whether to normalize the embedding vectors, defaults to True.
device: int
The number of devices, defaults to -1, which means using the
CPU. If the setting is not -1, the specified GPU device will
be used.
And you can also set the above parameters for the sentence embedding, for
example, you can set model to
'paraphrase-albert-small-v2' with AutoConfig:
from towhee import AutoPipes, AutoConfig
config = AutoConfig.load_config('sentence_embedding')
config.model = 'paraphrase-albert-small-v2'
sentence_embedding = AutoPipes.pipeline('sentence_embedding', config=config)
embedding = sentence_embedding('how are you?').get()The code AutoConfig.load_config('insert_milvus') will return an auto-set MilvusInsertConfig object that automatically configures some parameters of the insert Milvus pipeline:
host: str
Host of Milvus vector database, default is '127.0.0.1'.
port: str
Port of Milvus vector database, default is '19530'.
collection_name: str
The collection name for Milvus vector database, is required when inserting data into Milvus.
user: str
The user name for Cloud user, defaults to None.
password: str
The user password for Cloud user, defaults to None.
The code AutoConfig.load_config('search_milvus') will return an auto-set MilvusSearchConfig object that automatically configures some parameters of search Milvus pipeline:
host: str
Host of Milvus vector database, default is '127.0.0.1'.
port: str
Port of Milvus vector database, default is '19530'.
collection_name: str
The collection name for Milvus vector database, is required when inserting data into Milvus.
search_param: dict
The search parameter for Milvus vector database, defaults to None, more details can refer to it.
user: str
The user name for Cloud user, defaults to None.
password: str
The user password for Cloud user, defaults to None.